


三分之一个世纪前,加拿大学者们提出了经典的MoE模型神经网络结构,在人类探索AI的「石器时代」中,为后世留下了变革的火种。
近十年前,美国硅谷的互联网巨擎在理论和工程等方面,突破了MoE模型的原始架构,让这个原本被置于学术高阁的理念,化身成为了随后AI竞争的导火索。
如今,后发优势再一次来到了大洋此岸,以华为为代表的中国科技企业,纷纷提出对MoE架构的优化重组方案。尤其是华为的MoGE架构,不仅克服了MoE负载不均衡及效率瓶颈的弊病,还能够降本增效,便于训练和部署。
AI之战远未终结,但正如在其他领域中「多快好省」的中国产业底色一样,大模型这棵生于西方长于彼岸的科技树,也同样会被东方智慧经手后,进化为更加普适和亲切的工具。
近期,联合网将打造《华为技术披露集》系列内容,通过一连串的技术报告,首次全面披露相关的技术细节。
希望本系列内容能为业界起到参考价值,也希望更多人能与华为一起,共同打造长期持续的开放协作生态环境,让昇腾生态在中国茁壮成长。
《华为技术披露集》系列
VOL.8 :训练系统
现在,请大家一起数一下“1”、“2”。
OK,短短2秒钟时间,一个准万亿MoE大模型就已经吃透如何解一道高等数学大题了。
而且啊,这个大模型还是不用GPU来训练,全流程都是大写的“国产”的那种。
这,就是华为通过“昇腾+Pangu Ultra MoE”这套组合拳解锁的效果——
不仅实现了国产算力与国产模型全流程自主可控的训练闭环,更是在集群训练系统性能方面达到行业领先水平。
有多领先?来看一组数据:
· 预训练阶段:昇腾Atlas 800T A2万卡集群MFU提升至41%
· 后训练阶段:单CloudMatrix 384超节点吞吐达35K Tokens/s
值得一提的是,华为还首次把背后的一大秘籍给亮了出来。
具体来说,华为在这次发布的技术报告中,披露了在昇腾CloudMatrix 384超节点上,高效打通大稀疏比MoE强化学习后训练框架的关键技术。
此举可以说是让以强化学习(RL)为核心机制的后训练,进入到了超节点集群时代。
在深入华为Pangu Ultra MoE训练系统全流程之前,老规矩,我们还是先来了解一下此前的技术痛点。
整体来看,在当前的MoE预训练和强化学习后训练过程中所存在的挑战可以归结为六点:
并行策略配置困难:面对数据并行、张量并行、专家并行、流水线并行和序列并行等多种策略的组合选择,加上稀疏激活导致的负载不平衡因素,很难通过人工经验找到最优的并行配置方案。
All-to-All通信瓶颈:专家并行架构需要进行大规模的token路由交换,这不仅占用大量网络带宽资源,还会造成计算资源长时间空闲等待,严重影响整体训练效率。
系统负载分布不均:从注意力机制中序列长度的差异,到专家激活频率的不平衡,再到流水线并行中各阶段的负载分配问题,这些多层次的不均衡现象拖累了整个集群的性能表现。
算子调度开销过大:动态路由机制引入了大量高频率的小规模算子操作,增加了系统调度负担,降低了核心矩阵计算的比重,从而显著影响NPU的有效利用率。
训练流程管理复杂:强化学习后训练涉及多个模型实例和多种训练任务,包括MoE大模型的训练和推理阶段,整个流程的复杂性给资源分配和系统调度带来巨大挑战。
大规模扩展受限:强化学习过程中,训练与推理阶段的参数重新映射机制,以及各计算任务间复杂的数据通信流程,成为制约后训练大规模部署的主要瓶颈。
即使挑战如此之多,华为在这段技术报告中依旧是给出了一套完整的端到端全流程解法。
第一招:提升训练集群利用率
超大规模训练集群的高效部署,是提升预训练系统性能的关键所在。
为此,华为团队通过并行策略智能选择、计算通信深度融合、全局动态负载平衡等技术创新,显著提升了集群整体训练效率。
首先是建模仿真驱动的智能并行优化。
华为团队采用如下图所示的系统建模仿真框架,将原本需要大量人工试错的并行策略选择问题转化为精确的自动化搜索过程。
基于昇腾800T A2训练集群的硬件特性和约束条件,为Pangu Ultra MoE 718B模型确定了最优部署配置:
· 16路流水线并行(Pipeline Parallelism)进行模型层间切分
· 8路张量并行(Tensor Parallelism)专门处理注意力计算
· 32路专家并行(Expert Parallelism)实现专家模块分布式计算
· 2路虚拟流水线并行(Virtual Pipeline Parallelism)提升流水线效率
最终实现了与昇腾架构深度适配的最优化部署方案。
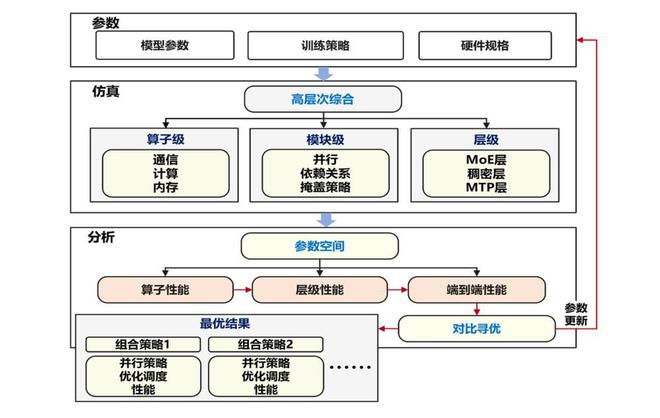
训练系统建模仿真流程
其次是Adaptive Pipe前反向通算掩盖。
为了突破并行扩展中的通信瓶颈问题,华为团队创新设计了昇腾网络拓扑适配的分层All-to-All通信去冗余机制,结合细粒度前反向计算重叠编排,成功将大规模MoE训练中的专家并行通信开销降至接近零暴露(
层次化专家并行通信:华为给出了与昇腾训练集群拓扑深度适配的多级通信策略。首先在节点间进行去冗余的token收集操作,避免相同token在低带宽的跨节点链路上重复传输;随后利用节点内高带宽优势,通过All-to-All通信实现token的冗余分发。这一分层设计显著提升了专家并行的整体通信效率。
自适应细粒度前反向掩盖:针对分层专家并行通信特点,设计了基于虚拟流水线并行(VPP)的细粒度前反向重叠掩盖策略。相比业界DualPipe掩盖方案,该策略将权重内存占用减少一半。通过进一步拆解MLP模块计算流程,充分利用分层专家并行通信中各级带宽相对独立的特性,实现算子执行顺序的自适应调优,最终将专家并行通信几乎完全隐藏(未掩盖比例仅为2%)。
最后是EDP Balance 全局动态负载均衡。
对于MoE模型,模型规模和集群规模的增长会导致专家计算、注意力计算以及各层间的负载不均衡问题相互叠加并被显著放大。当多种性能瓶颈同时出现时,通信同步等待会在系统中传播扩散,造成整体性能的严重恶化。
华为团队采用系统性的分析方法,深入剖析专家并行(EP)、数据并行(DP)、流水线并行(PP)各通信域中潜在的负载均衡挑战,提出了EDP全局负载均衡优化策略。
这个策略不仅通过专家负载预测和动态调节机制(如下图)实现设备间计算负载的精确平衡,还通过注意力数据重排技术进一步优化了数据并行域间的负载分布效果。
此外,团队将虚拟流水线并行(VPP)机制与硬件规格特点相结合,设计了最优混合并行架构,有效缓解了模型各层间计算负载分布不均的问题,大幅提升了整体训练效率。
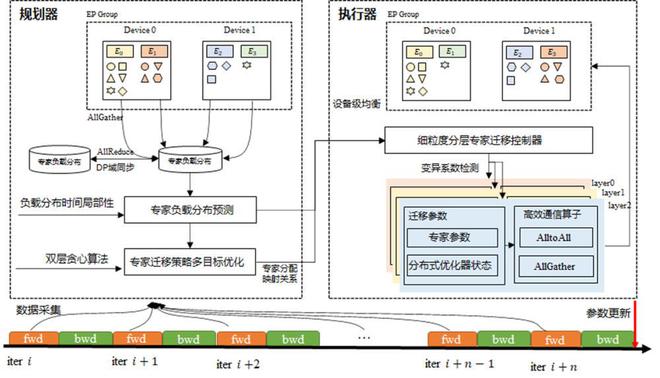
基于专家动态迁移的EP间负载均衡整体框架图
第二招:释放昇腾单节点算力
在昇腾超大规模集群优化实现突破性进展后,华为团队将优化焦点转向底层算子计算效率的深度挖潜。
这个阶段的核心工作围绕昇腾架构深度适配的训练算子加速展开,通过缓解Host资源瓶颈以及内存优化策略双重手段,成功将微批处理规模(MBS)提升至原来的两倍。
同时团队还对算子调度下发链路进行协同优化,最终实现了昇腾单节点算力的全面释放。
华为团队的“第二招”,同样包含三个细分内容;首先就是昇腾亲和的训练算子加速。
在大模型训练计算过程中,FlashAttention、MatMul以及Permute/Unpermute等向量操作算子的执行时间占据了算子总计算耗时的四分之三以上。
针对这些关键算子类型,华为团队充分利用昇腾微架构特性,通过算子流水线排布优化和数学等价冗余计算消除等核心技术手段,实现了训练算子性能的显著跃升。
其次是Host-Device协同的算子下发优化。
针对同步型间歇性Host-Bound和系统性持续性Host-Bound问题,华为团队充分发挥昇腾+鲲鹏异构系统协同优势,构建了分层优化体系来实现高效算子调度:
对于同步型Host-Bound问题,不仅有效消除了同步操作引发的Host资源瓶颈,在无法完全规避同步的场景下,还通过优化鲲鹏处理器的算子下发与调度策略,显著降低了同步后的Host-Bound开销。
对于系统性Host-Bound问题,则采用增大微批处理规模(MBS)、鲲鹏CPU NUMA亲和性优化等多维度协同手段,大幅提升算子下发效率。
通过算法与系统的深度协同优化,华为团队成功将MoE模型训练中的Host-Bound占比控制在2%以下,为超大规模模型训练探索出了全新的技术范式。
最后是Selective R/S-精准的内存手术方案。
华为团队构建了一个精密的内存优化框架:以丰富多样的通用化重计算策略和Swap机制作为“精密工具库”,涵盖从模块级到张量级的细粒度优化选项;配合精心设计的自适应内存管理机制作为“智能调度平台”。
这个框架针对Pangu Ultra MoE 718B模型训练需求,实现了多维度、定制化的内存资源精确调配。
通过构建最优内存优化策略组合,以精准的资源管理手段最大化释放内存空间,成功实现了超过70%的激活值内存节省。
即使在微批处理规模(MBS)翻倍带来的内存压力挑战下,这个方案依然为模型的长期稳定训练提供了可靠保障。
第三招:首次披露高性能可扩展RL后训练关键技术
华为团队针对强化学习训练中异构模型和多任务场景导致的资源利用率偏低问题,通过深入的系统分析和创新设计,提出了RL Fusion训推共卡技术。
这一技术支持训练推理共卡、全共卡等多种灵活部署模式(如下图),实现推理阶段资源调度的精细化可控管理,支持张量并行(TP)、数据并行(DP)、专家并行(EP)、流水线并行(PP)等多维并行策略的动态无缝切换。
可在秒级时间内完成训推状态转换,最终实现了RL后训练集群利用率翻倍的显著提升。
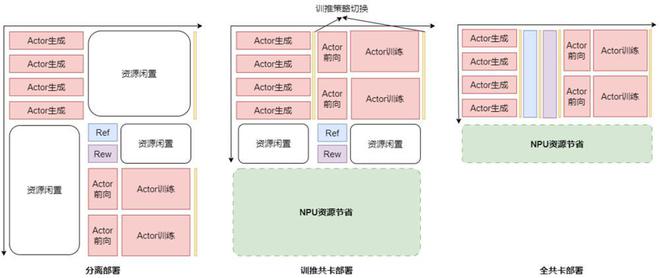
分离部署、训推共卡部署、全共卡部署资源利用率示意图
除此之外,华为团队还展示了面向大规模集群高效可扩展的后训练框架:
1. 摒弃全同步迭代方式,设计容忍梯度“陈旧性”的准异步机制StaleSync(如下图),让不同RL阶段的不同任务在“陈旧度阈值”内并行执行。在保证模型精度的前提下,系统整体训练吞吐提升50%。
2. 针对RL阶段多任务的处理需求,设计了分布式数据队列DistQueue,实现不同计算任务之间数据的拆分、缓存与动态读取。DistQueue对整个后训练过程中的数据进行管理,有效缓解不同计算任务之间的数据阻塞,为后训练任务高效调度提供数据支持。
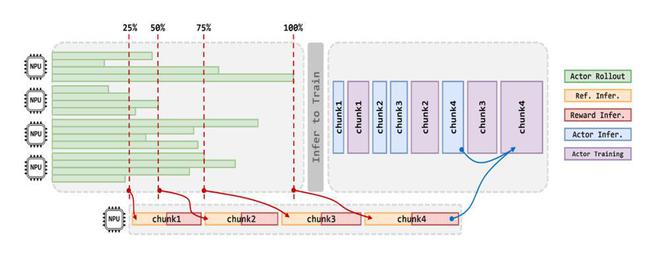
2秒就能让大模型吃透一道高数大题
通过预训练和RL后训练加速技术,华为团队基于MindSpeed、Megatron以及vLLM框架,打造了昇腾全流程高效训练系统。
这个系统可支持超大规模集群和超大规模MoE模型,并在Pangu Ultra MoE模型训练中实现了端到端的流畅训练。
Pangu Ultra MoE模型拥有7180亿参数量,具有大稀疏比和高综合性能的显著特点。
其架构包含61层Transformer,前3层为稠密层,后58层为MoE层。模型隐层维度达7680,配备256个路由专家和1个共享专家,专家隐层维度为2048。
在预训练阶段,华为团队使用6K - 10K卡的昇腾800T A2集群对Pangu Ultra MoE进行训练。在序列长度为8K、万卡训练集群的条件下,模型算力利用率(MFU)创下新高,达到了41%。上述训练系统具有很强的泛化性,可高效扩展至更大规模参数模型和更大规模卡数集群,同时如果配合昇腾CloudMatrix 384超节点的高速互联特性,预计可支撑训练集群MFU > 50%,相关技术迭代实践结果也将在日后技术报告中发布。
而在RL后训练阶段,于Pangu Ultra MoE昇腾CloudMatrix 384超节点集群的后训练中,采用训练推理混合并行策略(训练:PP16/VPP2/EP32/TP8,推理:PP1/EP64/TP1),并结合异步RL算法与训练框架系统的协同创新,实现了每超节点35K Tokens/s的高吞吐能力。同时支持高效扩展超过4K卡的集群,这一效率相当于每2秒就能吃透一道高等数学大题,实现了昇腾超节点吞吐的新突破。
以上便是华为Pangu Ultra MoE训练系统全流程的深度揭秘了。
本内容为作者独立观点,不代表联合网立场。未经允许不得转载,授权事宜请联系 hezuo@huxiu.com
本文来自联合网,原文链接:
https://www.huxiu.com/article/4408748.html?f=jinritoutiao
平台声明:该文观点仅代表作者本人,联合网系信息发布平台。发布者:联合网,转转请注明出处:https://www.anesthesia.org.cn/16219.html